

Lo admito: me encantan las auditorías técnicas SEO. Podéis temblar ante la idea de analizar un sitio buscando los posibles problemas de arquitectura, pero es una de mis actividades favoritas – una búsqueda de tesoros SEO.
Para la gente normal, el proceso general de auditoría del sitio puede ser desalentador y consumir mucho tiempo, pero con herramientas como la SEO Spider de Screaming Frog SEO, la tarea puede ser más fácil tanto para los novatos y profesionales del seo por igual. Con una interfaz muy fácil de usar, Screaming Frog puede ser muy fácil de usar, pero la variedad de opciones de configuración y funcionalidad puede hacer que sea difícil saber por dónde empezar.
Con eso en mente, he creado esta guía comprensiva de Screaming Frog para mostrar las diversas maneras en que SEO, PPC y otras personas de marketing pueden utilizar la herramienta para auditorías de sitio, investigación de palabras clave, análisis competitivo, construcción de enlaces y mucho más!
¿Necesitas una optimización onpage de tu web?
Rastreo Básico
Cómo rastrear un sitio entero
De forma predeterminada, Screaming Frog sólo rastrea el dominio que se introduce. Cualquier subdominio adicional que encuentre la araña será visto como enlaces externos. Para rastrear subdominios adicionales, debe cambiar los ajustes en el menú Spider Configuration. Al seleccionar’ Crawl All Subdomains‘, te asegurarás de que la araña rastrea cualquier enlace que apunte a otros subdominios en tu sitio.
Paso 1:
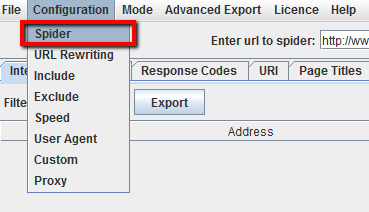
Paso 2:
Para que tu rastreo sea más rápido, no compruebes imágenes, CSS, JavaScript, SWF o enlaces externos.
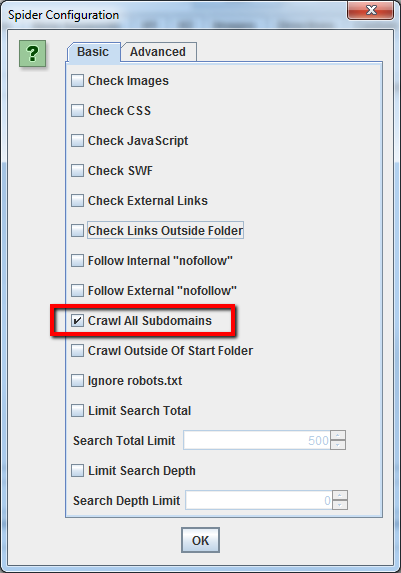
Cómo rastrear un solo subdirectorio
Si desea limitar su rastreo a una sola carpeta, simplemente ingrese la URL y presione el botón de inicio sin cambiar ninguna de las configuraciones predeterminadas. Si ha sobrescrito los ajustes predeterminados originales, reinicie la configuración predeterminada en el menú «Archivo».
Si desea iniciar su rastreo en una carpeta específica, pero desea continuar rastreándolo el resto del subdominio, asegúrese de seleccionar’ Crawl Outside Of Start Folder‘ en la configuración de «Spider Configuration» antes de ingresar su URL de inicio específico.
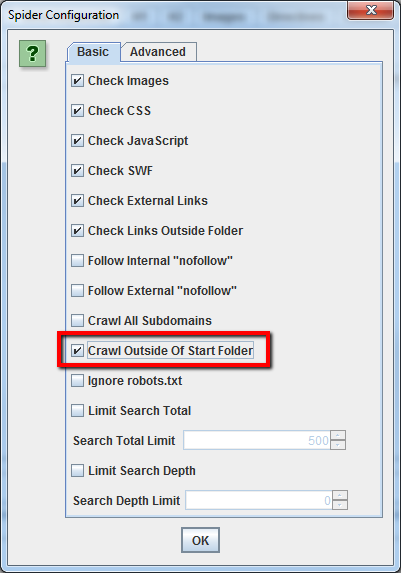
Cómo rastrear un conjunto específico de subdominios o subdirectorios
Si desea limitar tu rastreo a un conjunto específico de subdominios o subdirectorios, puede utilizar expresiones de RegEx para establecer esas reglas en las configuraciones Incluir o Excluir del menú Configuración.
Exclusión:
En este ejemplo, hemos rastreado todas las páginas de havaianas. com excluyendo las páginas’ sobre’ de cada subdominio.
Paso 1:
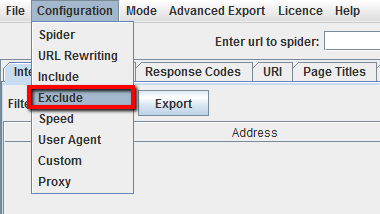
Paso 2:
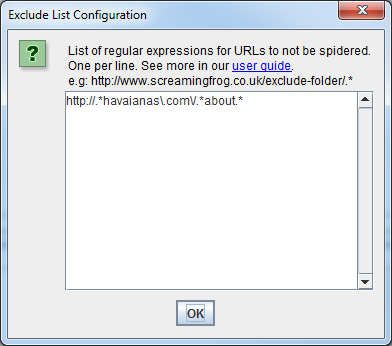
Inclusión:
En el siguiente ejemplo, sólo queríamos rastrear los subdominios en inglés en havaianas. com.
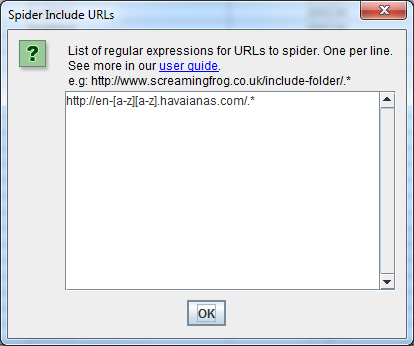
Quiero una lista de todas las páginas de mi sitio web
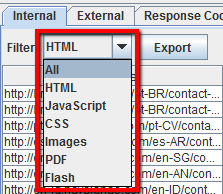
De forma predeterminada, Screaming Frog está configurado para rastrear todas las imágenes, JavaScript, CSS y archivos flash que encuentra la araña. Para rastrear sólo HTML, tendrá que deseleccionar’ Check Images’,’ Check CSS’,’ Check JavaScript’ y’ Check SWF’ en el menú Spider Configuration. Ejecutar la araña con estas configuraciones sin marcar le proporcionará, en efecto, una lista de todas las páginas de su sitio que tienen enlaces internos apuntando a ellas. Una vez que el rastreo haya terminado, vaya a la pestaña’ Interno’ y filtre sus resultados por’ HTML’. Haga clic en «Exportar», y tendrá la lista completa en formato CSV.
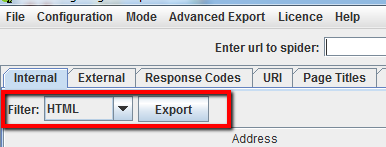
Cómo obtener una lista de dominios que mi cliente está redirigiendo actualmente a su moneysite
Ingresa la URL del moneysite en DomEye, luego haga clic en los enlaces de la tabla superior para encontrar sitios que comparten la misma dirección IP, nombre del servidor o código GA.
Desde aquí, puedes recopilar tu lista de URLs utilizando la extensión Google Chrome Scraper para encontrar todos los enlaces con el anchortext «visitar sitio». Si el scraper ya está instalado, puede acceder a él haciendo clic con el botón derecho del ratón en cualquier parte de la página y seleccionando ‘ Scarape similar…’. En la ventana emergente, tendrá que cambiar la consulta XPath a:
//a[text ()=’ visit site’]/@href
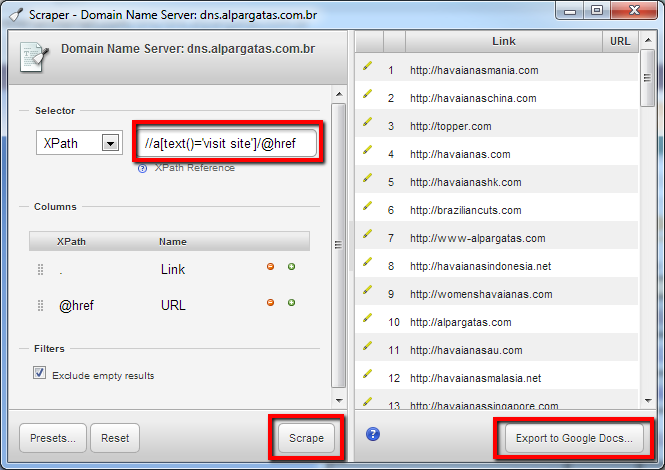
A continuación, pulsa’ Scrape’ y luego’ Exportar a Google Docs’. Desde Google Doc, puedes descargar la lista como archivo. csv.
Sube el archivo. csv a Screaming Frog, luego usa el modo’ List’ para comprobar la lista de URLs.
Cuando Sreaming Frog ha terminado, verá los códigos de estado en la pestaña’ Internal’, o puede buscar en la pestaña’ Response Codes’ (Códigos de respuesta) y filtrar por’ Redirection’ para ver todos los dominios que están siendo redirigidos al moneysite o a otro lugar.

Al cargar el. csv en Screaming Frog, debes seleccionar’ CSV’ como tipo de archivo, de lo contrario el programa se cerrará por error.
Consejo de PRO:
También puedes utilizar este método para identificar los dominios que tienen sus competidores y cómo los utilizan.
Cómo encontrar todos los subdominios de tu sitio y verificar los enlaces internos.
Introduzca la URL del dominio raíz en Censys.io y haga clic en la pestaña’ Subdominios’ para ver una lista de subdominios.
A continuación, utilice «Scrape similar» para recopilar la lista de URLs, utilizando la consulta XPath:
//a[text ()=’ visit site’]/@href
Exporta tus resultados a un CSV, luego carga el CSV en Screaming Frog usando el modo’ List’. Una vez que la araña haya terminado de correr, podrás ver los códigos de estado, así como cualquier enlace en las páginas de inicio de los subdominios, texto de anclaje y títulos de página duplicados, entre otras cosas.

Cómo rastrear una tienda online u otro sitio grande
Screaming Frog no está construido para rastrear cientos de miles de páginas, pero hay un par de cosas que puedes hacer para evitar romper el programa al rastrear sitios grandes. Primero, puede aumentar la memoria que trae por defecto Sreaming Frog.
En segundo lugar, puede desglosar el rastreo por subdirectorio o sólo rastrear ciertas partes del sitio utilizando la configuración Incluir/Excluir.
En tercer lugar, puede elegir no rastrear imágenes, JavaScript, CSS y flash. Desmarcando estas opciones en el menú Configuración.
Consejo de PRO:
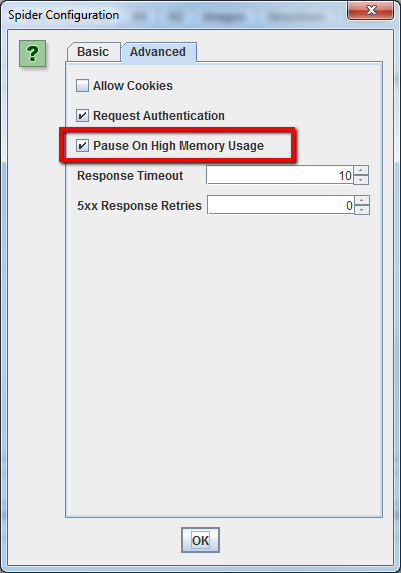
Hasta hace poco, es posible que hayas comprobado que tus rastreos se agotan al rastrear sitios grandes, sin embargo con las nuevas versiones de Screaming Frog, puedes decirle al programa que haga una pausa en el uso de memoria. Este ajuste de seguridad ayuda a evitar que el programa se colapse antes de que tenga la oportunidad de guardar los datos o aumentar la memoria.
Actualmente este ajuste viene por defecto, pero si necesitas rastrear un sitio grande, asegúrate de que la opción’ Pausa’ esté seleccionada en la pestaña’ Avanzado’ del menú Spider Configuration.
Cómo rastrear un sitio alojado en un servidor antiguo
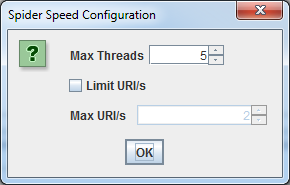
En algunos casos, es posible que los servidores antiguos no puedan gestionar un número predeterminado de solicitudes de URL por segundo. Para cambiar tu velocidad de rastreo, seleccione’ Velocidad’ en el menú Configuración, y en la ventana emergente, seleccione el número máximo de conexiones que deberían funcionar simultáneamente. Desde este menú, también puede elegir el número máximo de URLs solicitadas por segundo.
Consejo de PRO:
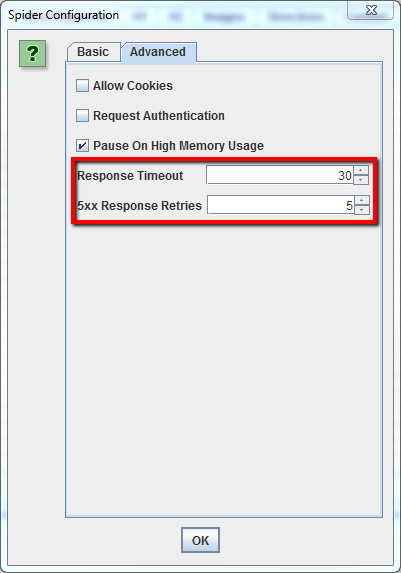
Si descubres que tu rastreo está causando muchos errores en el servidor, ve a la pestaña’ Advanced’ en el menú Spider Configuration, y aumenta el valor del’ Response Timeout’ y de los’ 5xx Response Retries’ para obtener mejores resultados.
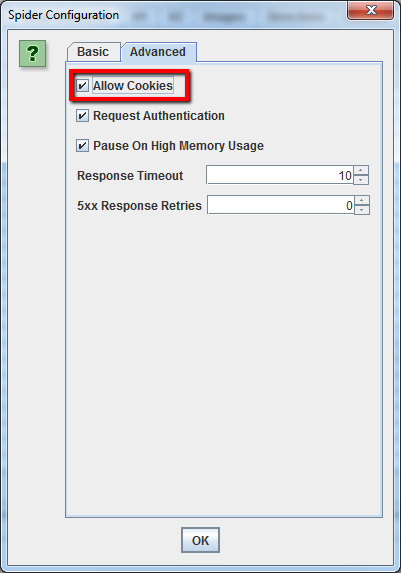
Cómo rastrear un sitio que requiere cookies
Aunque los robots de búsqueda no aceptan cookies, si usted está rastreando un sitio y necesita permitir cookies, simplemente seleccione’ Permitir cookies’ en la pestaña’ Avanzado’ del menú de configuración de araña.
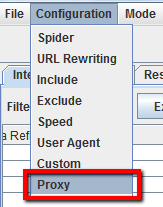
Cómo rastrear usando un proxy o un agente de usuario diferente
Para rastrear utilizando un proxy, seleccione’ Proxy’ en el menú’ Configuración’ e introduzca la información de su proxy.
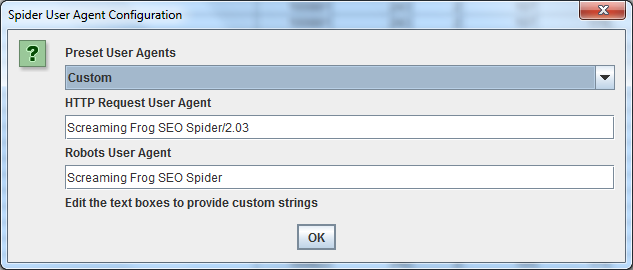
Para rastrear utilizando un agente de usuario diferente, seleccione’ User Agent’ en el menú’ Configuration’, luego seleccione un bot de búsqueda del menú desplegable o escriba las cadenas de su agente de usuario deseado.
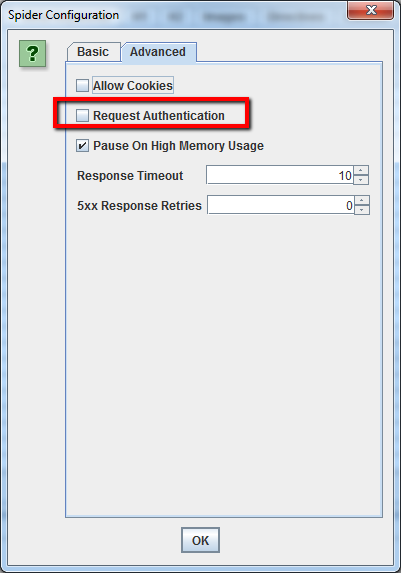
Cómo rastrear páginas que requieren autenticación
Cuando la araña de Screaming Frog se encuentra en una página protegida por contraseña, aparecerá una ventana emergente en la que podrá introducir el nombre de usuario y la contraseña necesarios.
Para desactivar las solicitudes de autenticación, deseleccione’ Solicitar Autenticación’ en la pestaña’ Avanzado’ del menú Configuración de Spider.
Auditoría de Enlaces Internos con Screaming Frog
Quiero información sobre todos los enlaces internos y externos de mi sitio (anchortext, directivas, enlaces por página, etc.)
Si no necesita comprobar las imágenes, JavaScript, flash o CSS en el sitio, deseleccione estas opciones en el menú Spider Configuration para ahorrar tiempo de procesamiento y memoria.
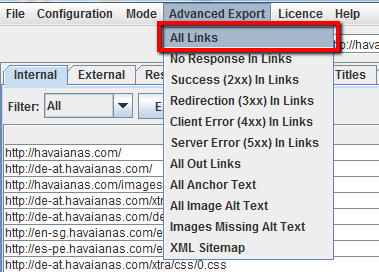
Una vez que Screaming Frog haya terminado de rastrear, utilice el menú Exportación avanzada para exportar un CSV de’ Todos los enlaces’. Esto le proporcionará todas las ubicaciones de los enlaces, así como el correspondiente texto de anclaje, directivas, etc.
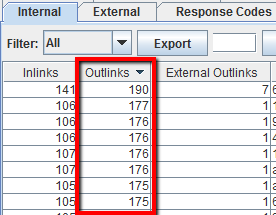
Para un recuento rápido del número de enlaces en cada página, vaya a la pestaña «Interna» y ordene por «Enlaces». Cualquier cosa que supere los 100, podría necesitar ser revisada.
¿Necesitas algo un poco más procesado? Aquí te dejo una tabla excel con datos gráficos que podrás utilizar para auditar tu sites y verlos de forma gáfica.
Cómo encontrar enlaces internos rotos en una página o sitio
Si no necesita comprobar las imágenes, JavaScript, flash o CSS del sitio, deseleccione estas opciones en el menú Spider Configuration para ahorrar tiempo de procesamiento y memoria.
Una vez que Screaming Frog haya terminado de gatear, clasifique los resultados de la pestaña’ Internos’ por’ Código de Estado’. Cualquier 404,301 u otros códigos de estado serán fácilmente visibles.
Al hacer clic en cualquier URL individual en los resultados de rastreo, verá un cambio de información en la ventana inferior del programa. Haciendo clic en la pestaña «En los enlaces» en la ventana inferior, encontrará una lista de páginas que están enlazando a la URL seleccionada, así como el texto de anclaje y las directivas utilizadas en esos enlaces. Puede utilizar esta función para identificar las páginas en las que es necesario actualizar los enlaces internos.
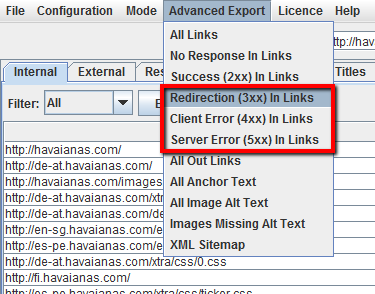
Para exportar la lista completa de páginas que incluyen enlaces rotos o redireccionados, seleccione’ Redirección (3xx) en los enlaces’ o’ Error de cliente (4xx) en los enlaces’ o’ Error de servidor (5xx) en los enlaces’ en el menú’ Exportación avanzada’, y obtendrá una exportación CSV de los datos.
Cómo encontrar enlaces salientes rotos en una página o sitio (o todos los enlaces salientes en general)
Después de deseleccionar’ Check Images’,’ Check CSS’,’ Check JavaScript’ y’ Check SWF’ en la configuración de Spider Configuration, asegúrate de que’ Check External Links’ permanezca seleccionado.
Una vez que la araña haya terminado de rastrear, haz clic en la pestaña’ Externa’ en la ventana superior, ordena por’ Código de Estado’ y fácilmente podrás encontrar URLs con códigos de estado distintos de 200. Al hacer clic en cualquier URL individual en los resultados de rastreo y, a continuación, haciendo clic en la pestaña «En enlaces» en la ventana inferior, encontrará una lista de páginas que están apuntando a la URL seleccionada. Puede utilizar esta función para identificar las páginas en las que es necesario actualizar los enlaces salientes.
Para exportar su lista completa de enlaces salientes, haga clic en «Exportar» en la pestaña interna. También puede configurar el filtro para exportar enlaces a archivos de imagen externos, JavaScript externo, CSS externo, archivos Flash externos y PDF externos. Para limitar su exportación a páginas, filtre por’ HTML’.
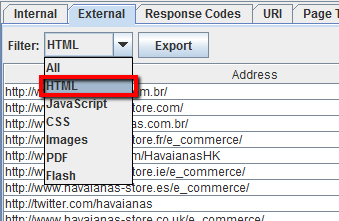
Para obtener una lista completa de todas las ubicaciones y texto ancla de los enlaces salientes, seleccione «Todos los enlaces salientes» en el menú «Exportación avanzada» y, a continuación, filtre la columna «Destino» en el CSV exportado para excluir su dominio.
Cómo encontrar enlaces redireccionados
Una vez que Sreaming Frog ha terminado de rastrear su site, seleccione la pestaña’ Códigos de respuesta’ en la ventana superior, luego filtre por’ Redirección (3xx)’. Esto le proporcionará una lista de todos los enlaces internos y salientes que están siendo redirigidos. Ordene por’ Código de Estado’ y podrá desglosar los resultados por tipo. Haga clic en la pestaña «In Links» en la ventana inferior para ver todas las páginas donde se usa el enlace redirigido.
Si exporta directamente desde esta pestaña, sólo verá los datos que se muestran en la ventana superior (URL original, código de estado y hacia dónde se redirige).
Para exportar la lista completa de páginas que incluyen enlaces redireccionados, tendrá que elegir’ Redirección (3xx) En Enlaces’ en el menú’ Exportación Avanzada’. Esto devolverá un CSV que incluye la ubicación de todos los enlaces redireccionados. Para mostrar sólo las redirecciones internas, filtre la columna’ Destino’ en el CSV para incluir sólo su dominio.
Auditar el Contenido de nuestro sitio con Screaming Frog
Cómo identificar páginas con contenido basura o «thin content»
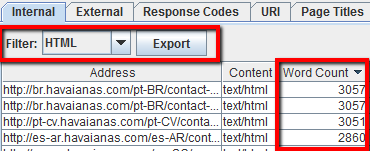
Una vez más rastreamos con Screaming Frog y terminado el rastreo de nuestros site, vamos a la pestaña «Interna», filtra por HTML y desplázate a la derecha hasta la columna «Número de palabras». Ordene la columna «Número de palabras» de abajo a arriba para encontrar páginas con poco contenido de texto. Puede arrastrar y soltar la columna «Conteo de palabras» a la izquierda para que coincida mejor con los valores de conteo de palabras bajas a las URLs apropiadas. Haga clic en «Exportar» en la pestaña «Interno» si prefiere manipular los datos en un CSV.
Consejo de PRO para tiendas online:
Mientras que el método de recuento de palabras anterior cuantificará el texto real en la página, todavía no hay forma de saber si el texto encontrado es sólo nombres de producto o si el texto está en un bloque de copia optimizado para palabras clave. Para calcular el número de palabras de sus bloques de texto, utilice ImportXML2 para rastrear los bloques de texto en cualquier url de la lista y contar los caracteres desde allí.
Quiero una lista de los enlaces de imágenes en una página en particular
Si ya ha rastreado todo un sitio o subcarpeta, simplemente seleccione la página en la ventana superior, luego haga clic en la pestaña «Info de Imagen» en la ventana inferior para ver todas las imágenes que se encontraron en esa página. Las imágenes aparecerán en la columna «Para».

Consejo de PRO:
Haga clic con el botón derecho del ratón en cualquier entrada de la ventana inferior para copiar o abrir una URL.
Alternativamente, también puede ver las imágenes en una sola página rastreando sólo esa URL. Asegúrate de que tu profundidad de rastreo está configurada a’ 1′ en la configuración de Spider Configuration, luego una vez que la página haya sido rastreada, haz clic en la pestaña’ Imágenes’, y verás cualquier imagen que la araña haya encontrado.
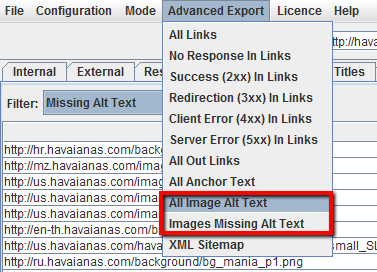
Por último, si prefiere un CSV, utilice el menú’ Exportación avanzada’ para exportar’ All Image Alt Text’ para ver la lista completa de imágenes, dónde se encuentran y cualquier texto alternativo asociado.

Cómo encontrar imágenes que carecen de texto alternatio o imágenes con texto alternativo largo
Primero, debe asegurarse de que’ Check Images’ esté seleccionado en el menú Spider Configuration. Una vez que la araña haya terminado de gatear, vaya a la pestaña’ Imágenes’ y filtre por’ Falta de Texto Alt’ o’ Texto Alt Más de 100 Caracteres’. Puede encontrar las páginas donde se encuentra cualquier imagen haciendo clic en la pestaña’ Info de Imagen’ en la ventana inferior. Las páginas aparecerán en la columna «De».
Alternativamente, en el menú’ Exportación avanzada’ puede ahorrar tiempo y exportar,’ All Image Alt Text’ o’ Images Missing Alt Text’ en un CSV. El archivo resultante le mostrará todas las páginas donde cada imagen se utiliza en el sitio.
Cómo encontrar cada archivo CSS en mi sitio web
En el menú Spider Configuration, seleccione’ Check CSS’ antes de rastrear, luego cuando el rastreo haya terminado, filtre los resultados en la pestaña’ Internal’ por’ CSS’.
Cómo encontrar todos los archivos JavaScript en mi sitio web
En el menú Spider Configuration, seleccione’ Check JavaScript’ antes de rastrear, luego cuando el rastreo haya terminado, filtre los resultados en la pestaña’ Internal’ por’ JavaScript’.
Cómo identificar todos los plugins de jQuery utilizados en el sitio y en qué páginas se usan
Primero, asegúrese de que’ Check JavaScript’ esté seleccionado en el menú Spider Configuration (Configuración de araña). Una vez que la araña haya terminado de rastrear, filtre la pestaña’ Internal’ por’ JavaScript’, luego busque’ jquery’. Esto le proporcionará una lista de archivos de plugin. Ordene la lista por la’ Dirección’ para una visualización más fácil si es necesario, luego vea’ InLinks’ en la ventana inferior o exporte los datos a un CSV para encontrar las páginas donde se usa el archivo. Estos estarán en la columna «De».

Alternativamente, puede utilizar el menú’ Exportación avanzada’ para exportar un CSV de’ Todos los enlaces’ y filtrar la columna’ Destino’ para mostrar sólo las URLs con’ jquery’.
Consejo de PRO:
No todos los plugins jQuery son malos para SEO. Si ves que un sitio usa jQuery, la mejor práctica es asegurarse de que el contenido que quieres indexado está incluido en la fuente de la página y se sirve cuando se carga la página, no después. Si todavía no estás seguro, busca en Google el plugin para obtener más información sobre cómo funciona.
Cómo encontrar dónde está incrustado el flash in situ
En el menú Spider Configuration, seleccione’ Check SWF’ antes de rastrear, luego cuando el rastreo haya terminado, filtre los resultados en la pestaña’ Internal’ por’ Flash’.
Postdata: Con este método sólo encontrarás los archivos SWF que están enlazados en una página. Si el flash se pulsa a través de JavaScript, necesitará utilizar un filtro personalizado.
Cómo encontrar los archivos PDF internos enlazados in situ
Una vez que la araña haya terminado de rastrear, filtre los resultados en la pestaña’ Internal’ por’ PDF’.
Cómo entender la estructura del contenido dentro de un sitio o grupo de páginas
Si desea encontrar páginas en su sitio que contengan un tipo específico de contenido, establezca un filtro personalizado para una huella HTML que sea exclusiva de esa página. Esto tiene que ser configurado *antes* de poner en marcha un nuevo rastreo con Screaming Frog.
Cómo encontrar páginas que tienen botones de social sharing
Para encontrar páginas que contengan botones de social sharing, necesitará establecer un filtro personalizado antes de ejecutar la araña. Para establecer un filtro personalizado, vaya al menú Configuración y haga clic en’ Personalizar’. Desde allí, introduzca cualquier fragmento de código desde la fuente de la página.
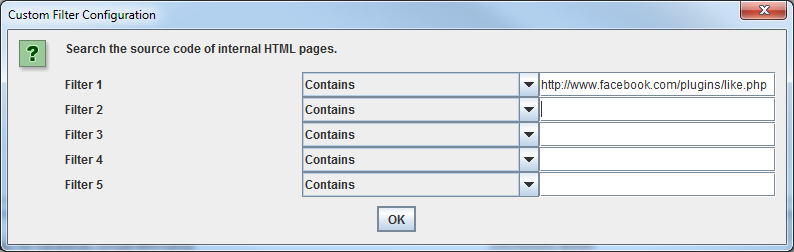
En el ejemplo anterior, quería encontrar páginas que contenían un botón «Me gusta» de Facebook, así que creé un filtro para http://www.facebook.com/plugins/like.php.
Cómo encontrar páginas que usan iframes
Para encontrar páginas que usan iframes, configure un filtro personalizado para <iframe antes de ejecutar la araña.
Cómo encontrar páginas que contienen contenido de vídeo o audio incrustado
Para encontrar páginas que contengan contenido de vídeo o audio incrustado, configure un filtro personalizado para un fragmento del código incrustado de Youtube o cualquier otro reproductor multimedia que se utilice en el sitio.
Metadatos y directivas
Cómo identificar páginas con títulos de página largos, metadescripciones o URLs
Una vez que la araña haya terminado de rastrear nuestro site, vaya a la pestaña’ Títulos de página’ y filtre por’ Más de 70 caracteres’ para ver los títulos de página que son demasiado largos. Puede hacer lo mismo en la pestaña’ Meta Descripción‘ o en la pestaña’ URI’.

Cómo encontrar títulos de página, metadescripciones o URLs duplicados
Una vez que la araña haya terminado de gatear, vaya a la pestaña’ Títulos de página’, luego filtre por’ Duplicar’. Puedes hacer lo mismo en las pestañas’ Meta Descripción’ o’ URI’.

Cómo encontrar contenido duplicado y/o URLs que necesitan ser reescritas/direccionadas/canonicalizadas
Después de que la araña haya terminado de rastrear, vaya a la pestaña’ URI’, luego filtre por’ Subrayados’,’ mayúsculas’ o’ Caracteres no ASCII’ para ver las URLs que potencialmente podrían ser reescritas a una estructura más estándar. Filtra por’ Duplicar’ y verás todas las páginas que tienen múltiples versiones de URL. Filtre por’ Dinámico’ y verá las URLs que incluyen parámetros.
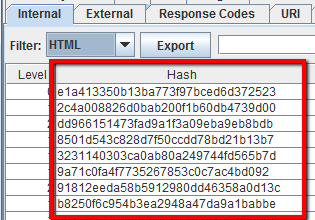
Además, si vas a la pestaña «Interno», filtra por «HTML» y desplázate a la columna «Hash» en el extremo derecho, verás una serie única de letras y números para cada página. Si hace clic en «Exportar», puede utilizar el formato condicional en Excel para resaltar los valores duplicados de esta columna, mostrando finalmente páginas que son idénticas.
Cómo identificar todas las páginas que incluyen metadirectivas por ejemplo: nofollow/noindex/noodp/canonical etc.
Finalizado el rastreo realizado por Screaming Frog, haga clic en la pestaña «Directivas». Para ver el tipo de directiva, simplemente desplácese hacia la derecha para ver qué columnas están llenas, o utilice el filtro para encontrar cualquiera de las siguientes etiquetas:
- index
- noindex
- follow
- nofollow
- noarchive
- nosnippet
- noodp
- noydir
- noimageindex
- notranslate
- unavailable_after
- refresh
- canonical
Cómo verificar que el archivo robots. txt está funcionando como se desea
De forma predeterminada, Screaming Frog cumplirá con robots.txt. Como prioridad, seguirá las instrucciones hechas específicamente para el agente usuario de Screaming Frog. Si no hay directivas específicas para el agente de usuario de Screaming Frog, entonces la araña seguirá cualquier directiva para Googlebot, y si no hay directivas específicas para Googlebot, la araña seguirá las directivas globales para todos los agentes de usuario.
La araña sólo seguirá un conjunto de directivas, por lo que si hay reglas establecidas específicamente para Screaming Frog sólo seguirá esas reglas, y no las reglas para Googlebot o cualquier regla global. Si desea bloquear ciertas partes del sitio desde la araña, utilice la sintaxis normal de robots. txt con el agente de usuario’ Screaming Frog SEO Spider‘. Si desea ignorar robots.txt, simplemente seleccione esta opción en los ajustes de configuración de Spider Configuration.
Cómo encontrar o verificar la marcación de Schema u otros microdatos en mi sitio web
Para encontrar todas las páginas que contienen marcas de Schema o cualquier otro microdato, necesita usar filtros personalizados. Simplemente haga clic en’ Personalizar’ en el menú de configuración e introduzca la huella que está buscando.
Para encontrar todas las páginas que contienen marcas de Schema, simplemente añada el siguiente fragmento de código a un filtro personalizado: itemtype=http://schema.org
Para encontrar un tipo específico de microdato, tendrá que ser más específico. Por ejemplo, usando un filtro personalizado para’ span itemprop= «ratingValue»‘ obtendrá todas las páginas que contienen la marcación de Schema buscada.
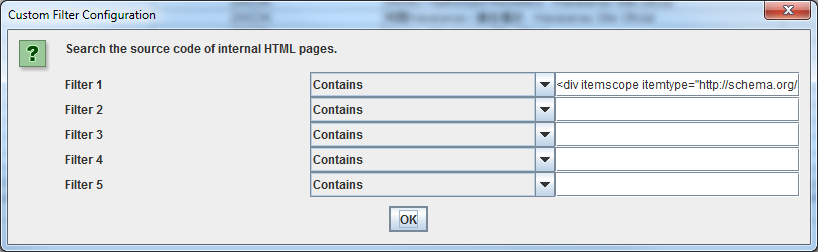
Cuando la araña haya terminado de rastrear, seleccione la pestaña’ Custom’ en la ventana superior para ver todas las páginas que contienen ese footprint. Si has introducido más de un filtro personalizado, puedes ver cada uno de ellos cambiando el filtro en los resultados.
Mapa del sitio
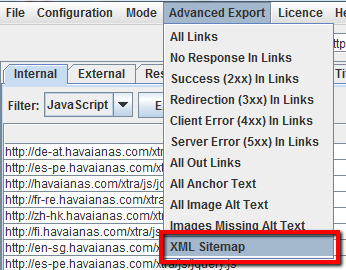
Cómo crear un Sitemap XML
Una vez que la araña haya terminado de rastrear tu sitio, haga clic en el menú’ Exportación avanzada’ y seleccione’ XML Sitemap’.
Guarda tu mapa del sitio y ábralo con Excel. Seleccione’ Sólo lectura’ y abra el archivo’ Como una tabla XML’. Puede recibir una alerta de que no se puede asignar un determinado esquema a una hoja de trabajo. Simplemente presione «Sí».
Ahora que su Sitemap está en forma de tabla, puede editar fácilmente la frecuencia de cambio, la prioridad y otros valores. Asegúrese de comprobar que el Sitemap sólo incluye una versión única y preferida (canónica) de cada URL, sin parámetros u otros factores de duplicación. Una vez realizados los cambios necesarios, vuelva a guardar el archivo como un archivo XML.
Cómo comprobar mi Sitemap XML existente
Primero, necesitará tener una copia del Sitemap. Puede guardar cualquier Sitemap activo visitando la URL y guardando el archivo, o importándolo en Excel.
Una vez que haya guardado el archivo XML en su ordenador, vaya al menú «Mode» en Screaming Frog y seleccione «List». Luego, haga clic en’ Seleccionar Archivo’ en la parte superior de la pantalla, elija su archivo e inicie el rastreo. Una vez que la araña haya terminado de rastrear, podrás encontrar cualquier redirección, 404 errores, URLs duplicadas y más «Sitemap dirt» en la pestaña’ Internal’.
Cómo solucionar problemas de nuestro site con Screaming Frog
Cómo identificar por qué ciertas secciones de mi sitio no están siendo indexadas
¿T preguntarás por qué ciertas páginas de tu site no están siendo indexadas? Primero, asegúrate de que no se hayan introducido accidentalmente en robots.txt o etiquetados como noindex.
A continuación, asegurate de que las arañas pueden acceder a las páginas revisando sus enlaces internos. Una vez que la araña haya rastreado su sitio, simplemente exporte la lista de URLs internas como un archivo CSV, usando el filtro’ HTML’ en la pestaña’ Internal’.
Abra el archivo CSV y, en una segunda hoja, pegue la lista de URLs que no están siendo indexadas o que no están bien clasificadas. Utilice un VLOOKUP para ver si las URLs de su lista en la segunda hoja se encuentran en el rastreo.
Consejo PRO:
Si realmente quieres ser relamente técnico y dejar a tu cliente con la boca abierta, prueba a utilizar la herramienta Google Doc/Excel Páginas no indexadas de Google, que, en un par de minutos, puede proporcionarte las posibles razones por las que determinadas páginas no están indexadas o rankeadas.
Cómo comprobar si la migración/rediseño de mi sitio tuvo éxito
Sorpresa!!!!!!!. También podemos utilizar Scraeming Frog para comprobar si las viejas URLs están siendo redireccionadas usando el modo’ Lista’ para comprobar los códigos de estado. Si las URLs viejas están lanzando 404′ s, entonces usted sabrá qué URLs todavía necesitan ser redireccionadas.
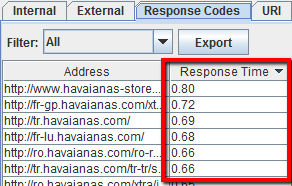
Cómo encontrar las páginas de carga lenta en mi sitio
Bien, ahora rastrea tu sitio, vaya a la pestaña’ Códigos de respuesta’ y ordene por la columna’ Tiempo de respuesta’ de arriba a abajo para encontrar páginas que puedan estar sufriendo una velocidad de carga excesiva.
Cómo encontrar malware o spam en mi sitio web
En primer lugar, deberá identificar la huella del malware o el spam. A continuación, en el menú Configuración, haga clic en’ Personalizar’ e introduzca la huella que está buscando.
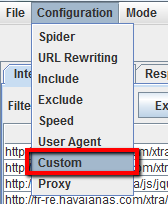
Puede introducir hasta 5 footprints diferentes por rastreo. Finalmente, presione OK y proceda a rastrear el sitio o la lista de páginas.
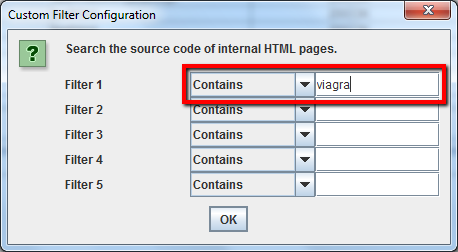
Cuando haya terminado de rastrear, seleccione la pestaña’ Custom’ en la ventana superior para ver todas las páginas que contienen su huella. Si ha introducido más de un filtro personalizado, puede ver cada uno de ellos cambiando el filtro en los resultados.
Cómo rastrear los metadatos para obtener una lista de páginas
Sí tienes una lista de urls, pero necesita más información sobre ellos? Configure su modo a’ Lista’, luego cargue su lista de URLs en formato. txt o. csv. Una vez que la araña esté lista, podrás ver los códigos de estado, enlaces salientes, recuentos de palabras y, por supuesto, los metadatos de cada página de tu lista.
Cómo rastrear un sitio para todas las páginas que contienen un footprint específico
Primero, tendrá que identificar la huella. A continuación, en el menú Configuración, haga clic en’ Personalizar’ e introduzca foorprint que está buscando.
Puede introducir hasta 5 footprint diferentes por rastreo. Finalmente, presiona OK y proceda a rastrear el sitio o la lista de páginas. En el siguiente ejemplo, quería encontrar todas las páginas que dicen «Por favor llame» en la sección de precios, así que encontré y copié el código HTML del código fuente de la página.
Cuando la araña haya terminado de rastrear, seleccione la pestaña’ Custom’ en la ventana superior para ver todas las páginas que contienen su huella. Si ha introducido más de un filtro personalizado, puede ver cada uno de ellos cambiando el filtro en los resultados.
Consejo de PRO:
Si estás extrayendo datos de productos de un sitio del cliente, podría ahorrarte algo de tiempo pidiéndole al cliente que extraiga los datos directamente de su base de datos. El método anterior está pensado para sitios a los que usted no tiene acceso directo.
Reescritura de URL con Screaming Frog
Cómo encontrar y eliminar el identificador de sesión u otros parámetros de mis URLs rastreadas
Para identificar URLs con identificadores de sesión u otros parámetros, simplemente rastree su sitio con la configuración predeterminada. Cuando la araña haya terminado, haz clic en la pestaña’ URI’ y filtra a’ Dinámico’ para ver todas las URLs que incluyen parámetros.
Para eliminar los parámetros que se muestran para las URL que rastrea, seleccione’ Reescritura de URL’ en el menú de configuración, luego en la pestaña’ Eliminar parámetros’, haga clic en’ Agregar’ para agregar cualquier parámetro que desee eliminar de las URLs, y presione’ Aceptar’. Tendrá que volver a ejecutar la araña con estos ajustes para que se produzca la reescritura.
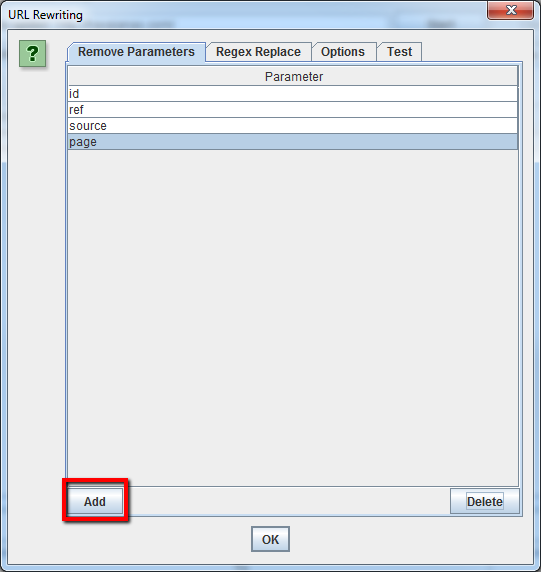
Cómo reescribir las URL rastreadas (por ejemplo: reemplazar. com con. co. uk, o escribir todas las URLs en minúsculas)
Para reescribir cualquier URL que rastrees, seleccione’ Reescribir URL’ en el menú de Configuración, luego en la pestaña’ Reemplazar Regex’, haga clic en’ Agregar’ para agregar RegEx a lo que desea reemplazar.
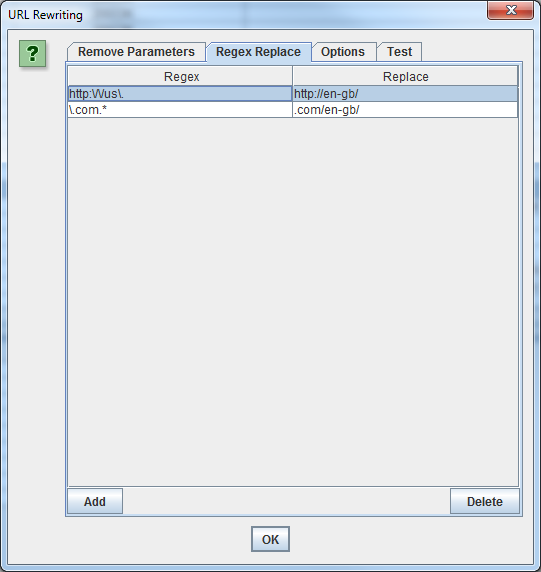
Una vez que hayas añadido todas las reglas deseadas, puedes probar tus reglas en la pestaña’ Test’ introduciendo una URL de prueba en el espacio etiquetado’ URL antes de volver a escribir’. La’ URL después de la reescritura’ se actualizará automáticamente de acuerdo con sus reglas.
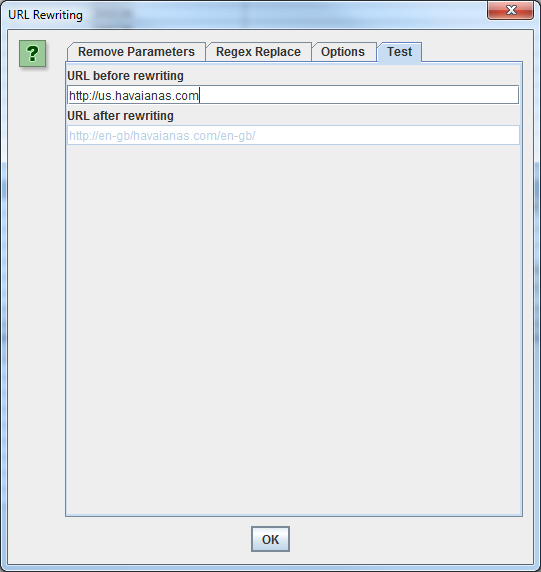
Si desea establecer una regla para que todas las URL se devuelvan en minúsculas, simplemente seleccione’ URLs en minúsculas descubiertas’ en la pestaña’ Opciones’. Esto eliminará cualquier duplicación mediante URLs en mayúsculas en el rastreo.
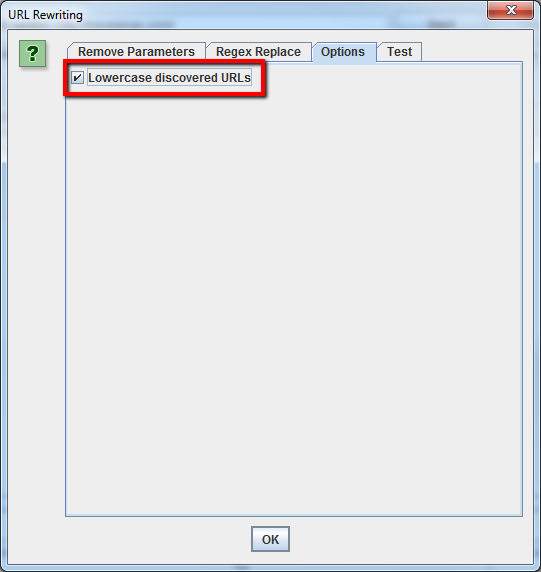
Recuerda que deberás ejecutar la araña con estos ajustes para que se produzca la reescritura de la URL.
Investigación de palabras clave con Screaming Frog
Cómo saber qué páginas valoran más mis competidores
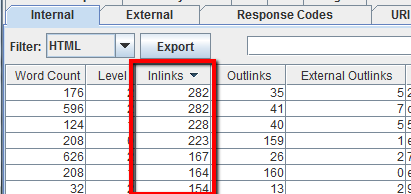
En términos generales, los competidores tratarán de difundir la popularidad de los enlaces y atraer tráfico a sus páginas más valiosas mediante enlaces internos. Las páginas más relevantes son aquellas que más enlaces internos están recibiendo. Rastrea cualquier sitio de tu competencia y luego selecciona la pestaña «Interna» en la columna «Enlaces» de la parte superior a la inferior, para ver qué páginas tienen los enlaces internos más importantes.
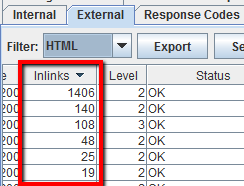
Para ver las páginas enlazadas desde el blog de su competidor, deseleccione’ Revisar enlaces fuera de la carpeta’ en el menú Spider Configuration y rastree la carpeta/subdominio del blog. A continuación, en la pestaña «Externa», filtre los resultados mediante una búsqueda de la URL del dominio principal. Desplácese hasta el extremo derecho y seleccione la lista por la columna «Enlaces» para ver qué páginas están enlazadas con más frecuencia.
Consejo de PRO:
Arrastre y suelte columnas a la izquierda o derecha para mejorar su vista de los datos.
Cómo saber qué anchortext utilizan mis competidores para el enlazamiento interno o interlinking
En el menú’ Exportación avanzada’, seleccione’ Todos los textos de anclaje’ para exportar un CSV que contenga todo el texto de anclaje en el sitio, dónde se utiliza y a qué está vinculado.
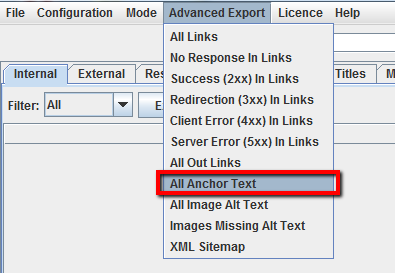
Cómo saber qué meta keywords (si los hay) mis competidores han añadido a sus páginas
Una vez que la araña haya terminado, mira en la pestaña’ Meta Keywords’ para ver cualquier meta keywords ha encontrado para cada página. Ordene por la columna’ Meta palabra clave 1′ para ordenar alfabéticamente la lista y separar visualmente las entradas en blanco, o simplemente exportar la lista completa.
Link Building
Cómo analizar una lista de posibles enlaces externos
Si has encontrado una lista de URLs que necesitan ser investigadas, puedes subirlas y rastrearlas en el modo’ Lista’ para reunir más información sobre las páginas. Cuando la araña haya terminado de rastrear, verifique los códigos de estado en la pestaña’ Códigos de respuesta’, y revise los enlaces salientes, tipos de enlace, texto ancla y directivas nofollow en la pestaña’ Enlaces salientes’ de la ventana inferior. Esto le dará una idea del tipo de sitios a los que esas páginas enlazan y cómo. Para revisar la pestaña’ Enlaces de salida’, asegúrese de que su URL de interés esté seleccionada en la ventana superior.
Por supuesto, querrá utilizar un filtro personalizado para determinar si esas páginas ya están enlazadas a usted.
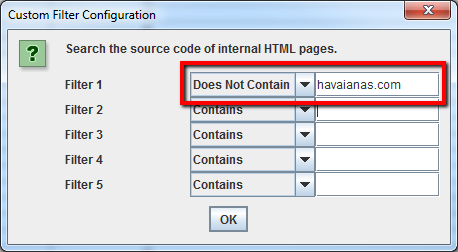
También puede exportar la lista completa de enlaces haciendo clic en’ All Out Links’ en el’ Advanced Export Menu’. Esto no sólo le proporcionará los enlaces a sitios externos, sino que también mostrará todos los enlaces internos en las páginas individuales de su lista.
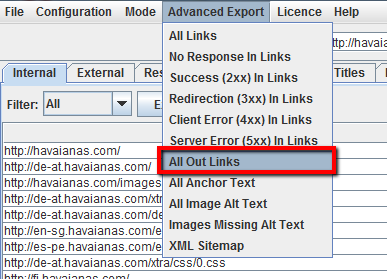
Cómo encontrar enlaces rotos con Screaming Frog
Entonces, ¿encontraste un sitio del que te gustaría tener un enlace? Utiliza Screaming Frog para encontrar enlaces rotos en la página deseada o en el sitio deseado, a continuación, te pones en contacto con el propietario del sitio, y le comentas que tiene un enlace roto y lesugiries tu sitio para reemplazar el enlace roto cuando corresponda, o simplemente ofrecer el enlace roto como una muestra de buena voluntad.
Cómo verificar mis backlinks y ver el anchortext con Scraeming Frog
Sube tu lista de backlinks y ejecuta la araña en modo’ List’. A continuación, exporta la lista completa de enlaces salientes haciendo clic en «Todos los enlaces salientes» en el «Menú de exportación avanzado». Esto te proporcionará las URLs y el anchortext para todos los enlaces en esas páginas. A continuación, puede utilizar un filtro en la columna «Destino» del CSV para determinar si su sitio está enlazado y qué texto de anclaje/alto se incluye.
Cómo asegurarse de que no soy parte de una red de enlaces
Estoy en el proceso de limpiar mis backlinks y necesito verificar que los enlaces se están eliminando según lo solicitado.
Establece un filtro personalizado que contenga la URL de tu dominio raíz, sube tu lista de vínculos de retroceso y ejecuta la araña en el modo’ Lista’. Cuando la araña haya terminado de rastrear, seleccione la pestaña’ Personalizar’ para ver todas las páginas que todavía están enlazando con usted.
Algunas perlas más de Screaming Frog
¿Sabía que al hacer clic con el botón derecho del ratón en cualquier URL de la ventana superior de sus resultados, podría hacer cualquiera de las siguientes acciones?
Copiar o abrir la URL
Vuelva a rastrear la URL o elimínela de su rastreo
Exportar información URL, In Links, Out Links o Image Info para esa página
Comprobar indexación de la página en Google, Bing y Yahoo
Consulta los vínculos de retroceso de la página en Majestic, OSE, Ahrefs y Blekko
Mira la versión caché / fecha caché de la página
Ver versiones anteriores de la página
Validar el HTML de la página
Abrir robots. txt para el dominio donde se encuentra la página
Buscar otros dominios en la misma IP
Del mismo modo, en la ventana inferior, haciendo clic con el botón derecho del ratón, puede hacerlo:
Copie o abra la URL en la columna’ Para’ para’ De’ de la fila seleccionada.
¡Dinos qué más has descubierto!
Para terminar, espero que esta guía te dé una mejor idea de lo que Sreaming Frog puede hacer por ti. Me ha ahorrado innumerables horas, así que espero que te ayude a ti también!
Por cierto, no estoy afiliado a Screaming Frog; sólo pienso que es una herramienta increíble.

- Caso de Éxito. Rejas Online, una Ecommerce - 21 marzo, 2024
- Caso de Éxito. Un Administrador de Fincas - 8 marzo, 2024
- ¿Qué es BrainWriting? - 22 enero, 2024


